Project IV: Credit Card Fraud Detection
In today’s world, we are on the express train to a cashless society. According to the World Payments Report, in 2016 total non-cash transactions increased by 10.1% from 2015 for a total of 482.6 billion transactions! That’s huge! Also, it’s expected that in future years there will be a steady growth of non-cash transactions.
Now, while this might be exciting news, on the flip-side fraudulent transactions are on the rise as well. Even with EMV smart chips being implemented, we still have a very high amount of money lost from credit card fraud:
Problem Statement:
The Credit Card Fraud Detection Problem includes modeling past credit card transactions with the knowledge of the ones that turned out to be fraud. This model is then used to identify whether a new transaction is fraudulent or not. Our aim here is to detect 100% of the fraudulent transactions while minimizing the incorrect fraud classifications.
Observations:
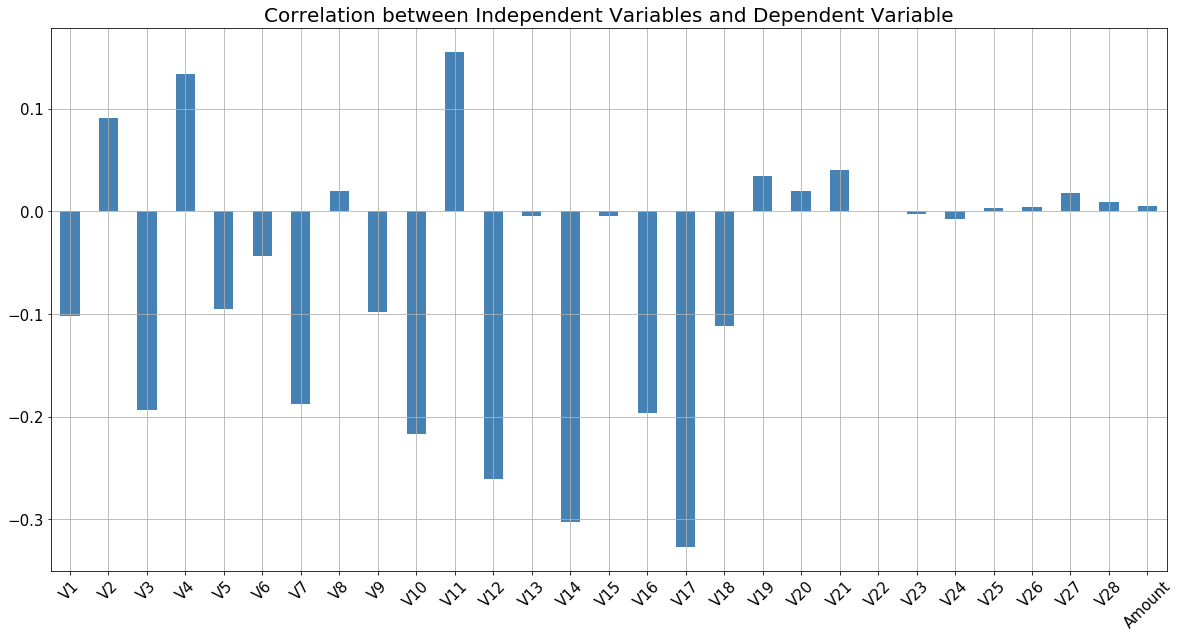
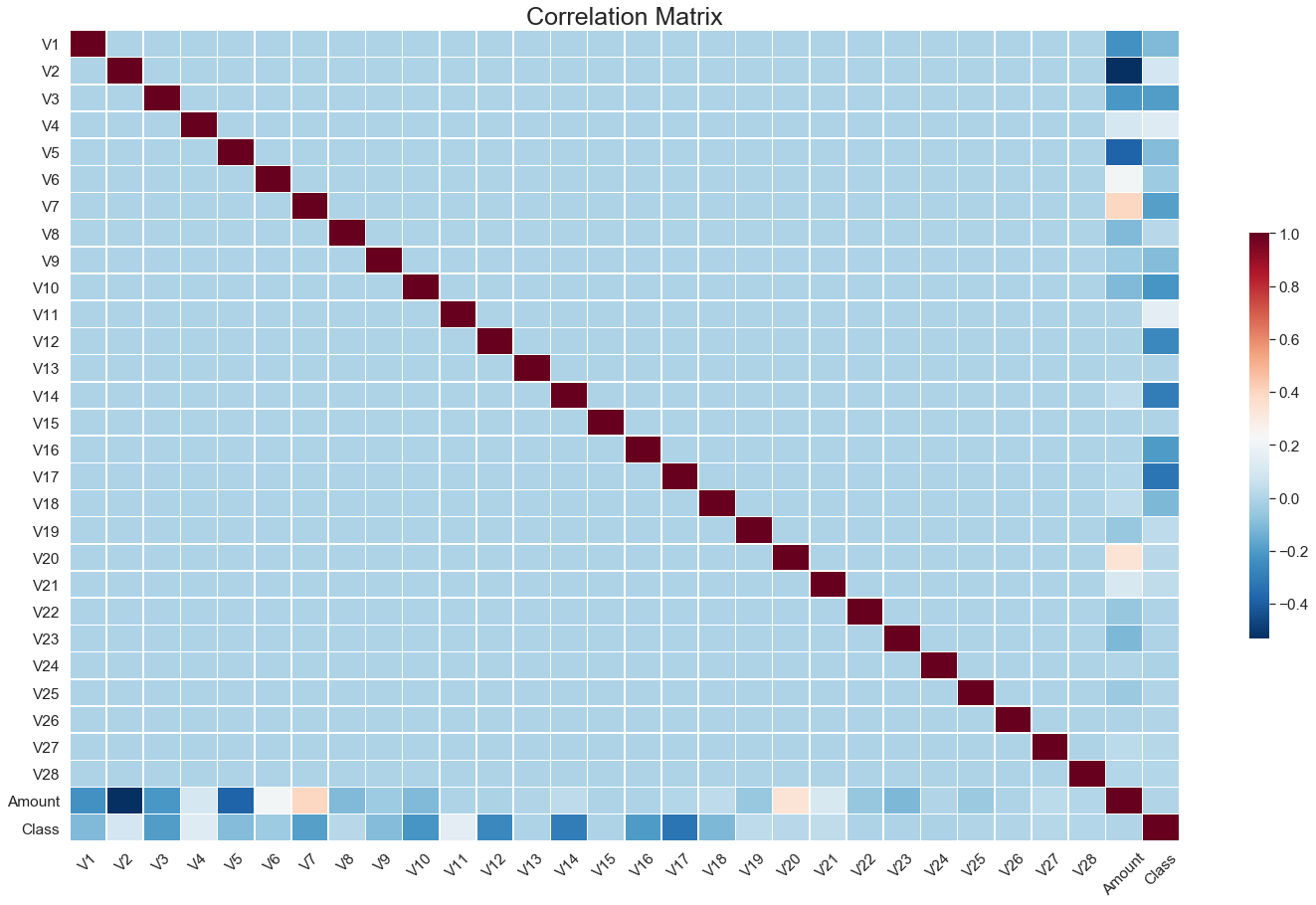
The data set is highly skewed, consisting of 492 frauds in a total of 284,807 observations. This resulted in only 0.172% fraud cases. This skewed set is justified by the low number of fraudulent transactions. The dataset consists of numerical values from the 28 ‘Principal Component Analysis (PCA)’ transformed features, namely V1 to V28. Furthermore, there is no metadata about the original features provided, so pre-analysis or feature study could not be done. The ‘Time’ and ‘Amount’ features are not transformed data. There is no missing value in the dataset.
Inferences drawn:
Owing to such imbalance in data, an algorithm that does not do any feature analysis and predicts all the transactions as non-frauds will also achieve an accuracy of 99.828%. Therefore, accuracy is not a correct measure of efficiency in our case. We need some other standard of correctness while classifying transactions as fraud or non-fraud. The ‘Time’ feature does not indicate the actual time of the transaction and is more of a list of the data in chronological order. So we assume that the ‘Time’ feature has little or no significance in classifying a fraud transaction. Therefore, we eliminate this column from further analysis.
Theory:
Credit Card Fraud Detection is a typical example of classification. In this process, we have focused more on analyzing the feature modeling and possible business use cases of the algorithm’s output than on the algorithm itself. We used the implementation of Binomial Logistic Regression Algorithm in the ‘ROCR’ package on the PCA transformed Credit Card Fraud data.
Some Definitions:
The following are essential definitions – in the current problem’s context – needed to understand the approaches mentioned later:
- True Positive: The fraud cases that the model predicted as ‘fraud.’
- False Positive: The non-fraud cases that the model predicted as ‘fraud.’
- True Negative: The non-fraud cases that the model predicted as ‘non-fraud.’
- False Negative: The fraud cases that the model predicted as ‘non-fraud.’
- Threshold Cutoff Probability: Probability at which the true positive ratio and true negatives ratio are both highest. It can be noted that this probability is minimal, which is reasonable as the probability of frauds is low.
- Accuracy: The measure of correct predictions made by the model – that is, the ratio of fraud transactions classified as fraud and non-fraud classified as non-fraud to the total transactions in the test data.
- Sensitivity: Sensitivity, or True Positive Rate, or Recall, is the ratio of correctly identified fraud cases to total fraud cases.
- Specificity: Specificity, or True Negative Rate, is the ratio of correctly identified non-fraud cases to total non-fraud cases.
- Precision: Precision is the ratio of correctly predicted fraud cases to total predicted fraud cases.