Predicting if the cancer diagnosis is benign or malignant based on several observations/features
Project I: Breast Cancer Classification
Breast cancer (BC) is one of the most common cancers among women worldwide, representing the majority of new cancer cases and cancer-related deaths according to global statistics, making it a significant public health problem in today’s society.
The early diagnosis of BC can improve the prognosis and chance of survival significantly, as it can promote timely clinical treatment to patients. Further accurate classification of a benign tumour can prevent patients from undergoing unnecessary treatments. Thus, the correct diagnosis of BC and the classification of patients into malignant or benign groups is the subject of much research. Because of its unique advantages in critical features detection from complex BC datasets, machine learning (ML) is widely recognized as the methodology of choice in BC pattern classification and forecast modelling.
Classification and data mining methods are an effective way to classify data. Especially in the medical field, where those methods are widely used in the diagnosis
Predicting if the cancer diagnosis is benign or malignant based on several observations/features
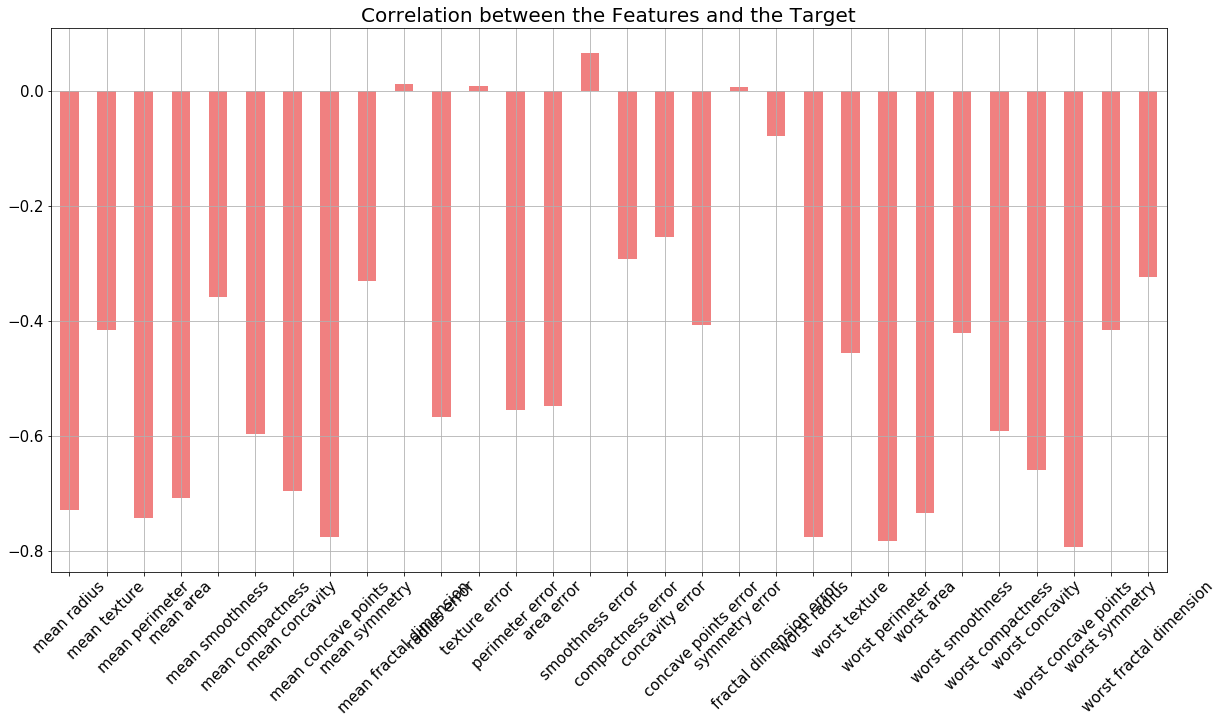
30 features are used, examples:
radius (mean of distances from center to points on the perimeter)
texture (standard deviation of gray-scale values)
perimeter
area
smoothness (local variation in radius lengths)
compactness (perimeter^2 / area - 1.0)
concavity (severity of concave portions of the contour)
concave points (number of concave portions of the contour)
symmetry
fractal dimension (“coastline approximation” - 1)
Datasets are linearly separable using all 30 input features